Background
Our data:
Kafka traffic topic filled with big data with many dynamic attributes (500k QPS, 12kb per message, 500+ attribtues) and encoded in JSON. The attributes are added dynamically by users through a config center UI.
Upstream Avro Integration
Our first solution is to encode the messages in Avro. Besides the cost savings that a binary encoding will provide, we also chose Avro for the following benefits over other encodings such as Proto or Thrift:
- The ability to write Avro messages without relying on code generation
- The libraries in Spark and Flink
- The schema registry service which can help us to maintain the schema
The first benefit is the most importance, because new attributes are added quite frequently through our UI (about a few new ones each week). Using Avro, we can dynamically update the schema each time a user adds a new field, without the need to generate new code and redeploy our program.
Our attribute adding logic now goes like this:
User adds new field -> backend updates schema on schema registry -> backend sends messages with new schema
Downstream Avro Integration
For downstream, we mainly use Flink, and the avro-confluent consumer is well documented. It will cache many old schemas, and call the schema registry each time it encounters a new schema ID, and parse the new messages accordingly. This ensures it can read old and new schema.
Job evolution
Upstream job able to write messages with new schema dynamically, check
Downstream job able to read new schema compatibly, check
Downstream job able to write new schema, ?
Most programs that consume Avro messages, typically deserializes it to a fixed inner object and the schema evolution ends there.

While most jobs just needs fixed fields and write to a fixed table, jobs needing all fields such as syncing to the Data Warehouse may like to add new fields whenever the upstream schema changes. So what can we do to make our job evolve together with the schema and push the schema evolution further downstream. This is what I call job evolution
- Use an envelop data structure. Basically use a map to store the dynamic values, but this goes against the principle of taking the keys out of each message, we will be basically back to using JSON.
- Use avro generic data object. For this one, it means we deserialize the Avro object as a generic Avro record while processing it in Flink before writing it out. This one requires a lot of code modification to make it work with Spark and Flink.
- Restart the job with updated code. This means we restart our jobs at intervals, with new code that writes to downstream table with new schema. This is the easiest to achieve because there is a high level language to represent jobs - SQL.
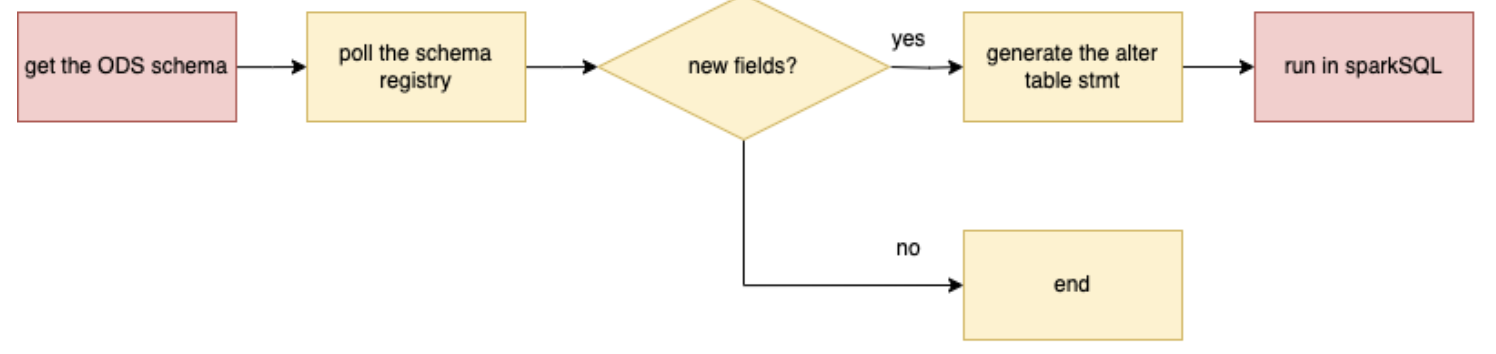
So a new pipeline for Flink job can look like this, similar strategy can also be applied to Spark:

However, a key consideration for job evolution is also downstream table structure, so we may also need to perform a DDL change after a fixed interval. An example for Spark will be something like this: